Tokenization drift is a subtle but critical issue in large language model inference. It occurs when minor surface-level differences in input text—such as spacing, line breaks, or punctuation—cause the tokenizer to generate entirely different token sequences. Because models are trained on specific tokenization patterns, any deviation can push the input outside the model's learned distribution, leading to unpredictable performance drops. This article explains the phenomenon in depth, using the GPT-2 tokenizer as an example, and provides actionable strategies to detect and mitigate tokenization drift.
1. What is tokenization drift and why does it matter?
Tokenization drift refers to the phenomenon where small, seemingly insignificant changes in input formatting—such as adding or removing a space before a word—result in a completely different set of token IDs being fed into a language model. This matters because the model's behavior is highly sensitive to the exact token sequence it receives. Even if the semantic meaning of the text remains unchanged, different tokens can shift the model's internal representation, causing it to produce inconsistent or degraded outputs. In production, this means a prompt that worked perfectly yesterday might fail today due to a minor formatting change in the input pipeline, even though the underlying data and logic are identical. Understanding tokenization drift is crucial for maintaining reliable model performance across different environments and use cases.
2. How does tokenization drift affect model performance beyond just token IDs?
The impact of tokenization drift goes deeper than simple ID mismatches. During instruction tuning, models learn not only the tasks themselves but also the structural patterns—specific separators, prefixes, and formatting conventions—in which those tasks are presented. When a prompt deviates from these learned patterns, the input falls outside the model's familiar distribution. The model still processes the input as best it can, but it was never optimized for such inputs. This often leads to unexpected behavior: slight changes in accuracy, loss of context, or altered attention patterns. For example, a model fine-tuned with leading spaces after separators may underperform if the spaces are omitted. The result is not confusion but a systematic shift in performance that is hard to diagnose without understanding the underlying tokenization.
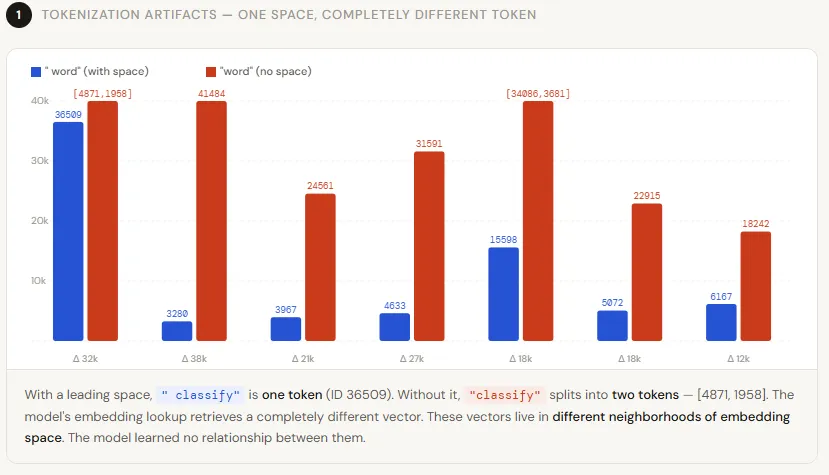
3. Can a single space really change token sequences? Show an example.
Yes, a single space can dramatically alter token sequences. Using the GPT-2 tokenizer (a Byte-Pair Encoding scheme similar to those used by GPT-4, LLaMA, and Mistral), encode the word "classify" with and without a leading space. Without the space, it splits into two tokens: [4871, 1958]. With a leading space, it becomes a single token: [36509]. This is not an isolated case—every word tested in a GPT-2 demo produces a different token ID depending on the presence of a leading space. Some words that are single tokens without a space become multiple tokens with a space, and vice versa. This means the model sees not only different IDs but also a different sequence length, which fundamentally changes how attention is computed for all subsequent tokens. Such artifacts can propagate through the entire prompt, leading to cascading effects on model output.
4. Why is the space prefix artifact so critical for tokenization drift?
The space prefix artifact arises because tokenizers like GPT-2 treat spaces as part of the token vocabulary. When a word is preceded by a space, the tokenizer often merges the space and the word into a single token, whereas without the space, the word may split differently. This is a deliberate design choice in Byte-Pair Encoding to preserve word boundaries, but it introduces sensitivity to whitespace. For production prompts, this means that whether you include a space after a colon, a newline, or a tab can shift the entire tokenization. Because many instruction-tuned models learn from datasets that follow consistent spacing conventions (e.g., always having a space after a separator), deviating from that convention pushes the input out of the model's learned distribution. The space prefix is especially critical because it affects every word in the sequence, making it one of the most common sources of tokenization drift.
5. How can you measure tokenization drift in your prompts?
To measure tokenization drift, you can build a simple drift metric by comparing the token sequences produced by a reference prompt (the one used during training or validation) and a target prompt. For each word or subword, compute the difference in token IDs and sequence lengths. A practical approach is to tokenize the same sentence with different formatting (e.g., with and without leading spaces) and calculate the cosine distance between the embedding vectors of the two token sequences. Alternatively, you can compute the Jaccard similarity of token sets or the sequence alignment cost. In the article, we implement a lightweight prompt optimization loop that evaluates multiple formatting variants and selects the one that minimizes drift relative to a known-good reference. This metric helps identify which formatting choices keep the input closest to the model's training distribution, thereby improving consistency.
6. How can you fix tokenization drift in practice?
Fixing tokenization drift requires a systematic approach to prompt formatting. First, establish a reference prompt that matches the formatting patterns used during the model's instruction tuning. If that data is unavailable, you can infer likely patterns by analyzing models that share the same tokenizer. Next, implement a prompt optimization loop that generates multiple variants of your input (varying spaces, line breaks, punctuation), tokenizes each, and selects the one that minimizes the drift metric. Tools like the GPT-2 tokenizer demo in the original article can help visualize differences. Finally, apply consistent formatting rules across all prompts in your pipeline: always include leading spaces after colons, use identical newline patterns, and avoid mixing tabs and spaces. By treating tokenization as a controlled variable, you can eliminate most drift and ensure reliable model behavior.
7. What are the best practices to avoid tokenization drift from the start?
To avoid tokenization drift proactively, adopt these best practices: 1) Always use the same tokenizer version as the model was trained with—mismatched tokenizers can cause drift even with identical text. 2) Standardize all input formatting: choose a single convention for spacing (e.g., always include a space after a separator) and stick to it. 3) Avoid relying on whitespace-sensitive constructs like leading spaces for indentation; instead, use explicit markers or templates. 4) Test your prompts against a reference dataset by comparing token sequences—automate this in CI/CD pipelines. 5) When fine-tuning, deliberately include a variety of formatting patterns to make the model robust to minor variations. 6) Use tokenizer inspection tools to visualize how your prompt is tokenized. By integrating these practices into your workflow, you can minimize tokenization drift and maintain consistent model performance across deployments.